한줄로 요약하면
같은 말 또 하면 ‘아까 말한 그거’라고 줄이고(LZ77)
‘아까 말한 그거’가 자주 나오면 아예 한 글자로 줄여버림(Prefix Code)
Gzip = 반복을 먼저 줄이고(LZ77) → 그 결과를 Prefix Code(허프만)로 비트까지 압축
gzip 내부는 DEFLATE라는 알고리즘을 씀
DEFLATE 뜻
inflate = 부풀리다 (압축 해제)
deflate = 찌그러뜨리다 (압축)
DEFLATE =
LZ77 (사전 기반 압축) + Huffman Coding (Prefix Code)
- 허프만은 반복 패턴을 직접 못 잡음
- LZ77은 구조를 줄임
- 허프만은 비트를 줄임
그래서 둘이 많이 쓰인다
자세히 알아보자
LZ77 — “반복을 숫자로 바꾼다”
이미 본 문자열이 또 나오면 그걸 다시 쓰지 말고 (얼마나 뒤로, 몇 글자)로 표현
예)
입력: ABABABAB
LZ77 결과: A B (2,2) (2,2) (2,2)
아직 비트 단위로는 안 줄었음→ 구조만 바꾼 상태

https://blog.codingconfessions.com/p/lz77-is-all-you-need?utm_source=chatgpt.com
LZ77 Is All You Need? Why Gzip + KNN Works for Text Classification
Decoding the Success of Gzip + KNN: The Central Role of LZ77
blog.codingconfessions.com
2.Huffman(허프만=사람) Coding
LZ77 결과를 보면:
- 어떤 literal
- 어떤 length
- 어떤 거리
- 가 엄청 반복됨
그래서:
자주 나오는 토큰 → 짧은 비트
드문 토큰 → 긴 비트
이걸 Prefix Code로 만듦.
핵심 포인트
- gzip은 Prefix Code만 사용
- 모든 코드는 리프 노드
- 디코딩 중 비트 읽다 리프 도달 = 즉시 확정
https://hi-guten-tag.tistory.com/98
[알고리즘] 탐욕법 - 허프만 코드 (Greedy Approach - Huffman Code)
1. 데이터 압축 문제 (The problem of data compression) 데이터 파일을 효율적으로 encoding 하기 위한 방법을 찾아내는 문제입니다. 데이터 파일은 통상적으로 이진 코드 (binary code)로 표현됩니다. 또한 각
hi-guten-tag.tistory.com
Prefix Code(접두사 코드)란?
어떤 코드도, 다른 코드의 시작(prefix)이 되면 안 된다.
(A↔B, A↔C, B↔C … 전부 포함)
디코딩할때 언제끊어져야하는지 명확하게 알 수 있어야함!
좋은예)
A = 0 B = 10 C = 110 D = 111
- 0으로 시작하는 코드는 A 하나뿐
- 10으로 시작하는 코드는 B 하나뿐
- 110과 111은 서로 첫 2비트가 같아도
- → 서로 접두사는 아님
나쁜예)
A = 0 B = 01 C = 011
여기서 문제는:
- 0 은 01의 접두사
- 01 은 011의 접두사
- → 두 군데에서 규칙 위반
Prefix(접두사 금지) 하면 숫자가 엄청 늘어나지않을까? 라는 의문
→ 상황에 따라 다르다고 하지만 보통은 아니라고 한다!
Prefix Code = 이진 트리 = 공간이 정해져 있음
이진 트리는 이런 성질이 있다:
- 깊이 1: 최대 2개
- 깊이 2: 최대 4개
- 깊이 3: 최대 8개 …
- 전부를 짧게 만들 수는 없지만
- “중요한 애들만” 짧게 만드는 건 가능
심볼 등장 확률
| A | 50% |
| B | 25% |
| C | 15% |
| D | 10% |
자주 나오는 심볼 → 짧은 코드
잘 안 나오는 심볼 → 긴 코드
A = 0
B = 10
C = 110
D = 111
A는 절반 나오니까 1비트
D는 거의 안 나오니까 3비트
평균 길이는 오히려 짧아짐
예제 데이터
JSON / 로그 / 코드에서 흔한 데이터
GET /api/user
GET /api/user
GET /api/user
패턴이 많이 반복됨
- GET
- /api/user
- 공백, 개행 이 똑같이 반복
1단계: LZ77 단계
“이미 앞에서 본 문자열이 다시 나오면 그 문자열을 다시 쓰지 말고
- (얼마나 뒤로 가면, 몇 글자냐)만 적자”
첫 줄
G E T / a p i / u s e r \\n
두 번째 줄
GET /api/user
LZ77은 “어? 이거 방금 전에 똑같은 게 있었는데?”
그래서 실제로는 이렇게 바꿈
(뒤로 14글자, 길이 14)
세 번째 줄도
(뒤로 14글자, 길이 14)
LZ77 결과 (개념적으로)
"GET /api/user\\n"
(14,14)
(14,14)
“문장을 좌표로 바꿔 적는다”
- 텍스트 → 토큰(token)으로 바뀜
- 토큰 종류:
- 문자 (G, E, T, …)
- 숫자쌍 (14,14)
하지만 아직 비트 수는 별로 안 줄었음❗❗❗
2단계: Huffman (Prefix Code) 단계
“(14,14) 이거 엄청 많이 나오네?”
“G, E, T 같은 글자도 자주 나오네?”
자주 나오는 것 → 짧은 이진수
(예시)
(14,14) → 0
'G' → 10
'E' → 110
'T' → 111
이건 Prefix Code라서:
- 겹치지 않음
- 어디서 끊어야 할지 명확
결과적으로 비트 스트림은?
10 110 111 ... 0 0
(14,14) → 0 (1비트) 'G' → 10 (2비트) 'E' → 110 (3비트) 'T' → 111 (3비트)
예시 상황
(14,14) 가 100번 등장
압축 전 (개념적)
- (14,14) 표현에 16비트 × 2 = 32비트라고 치면
- 100번 → 3200비트
압축 후
- (14,14) → 0 (1비트)
- 100번 → 100비트
32배 차이나 난다!
잘안나오는건 손해이긴 하지만 그래서 압축은 자주나오는 평균이 중요함!
반대로 왜 이미지, 영상은 잘 안 줄어드는 이유
JPEG, MP4는 이미 내부에서:
- 비슷한 픽셀
- 비슷한 패턴
- 을 자기들만의 방식으로 이미 압축함
어떻게 디코딩을 하느냐!
https://www.infinitepartitions.com/art001.html?utm_source=chatgpt.com
https://www.infinitepartitions.com/art001.html?utm_source=chatgpt.com
Dissecting the GZIP format In this article I describe the DEFLATE algorithm that GZIP implements and depends on. The DEFLATE algorithm uses a combination of LZ77, Huffman codes and run-length-encoding; this article describes each in detail by walking throu
www.infinitepartitions.com
어떻게 디코딩을 하느냐!!
압축 데이터 앞(또는 중간)에 ‘코드표’를 같이 넣어둔다.
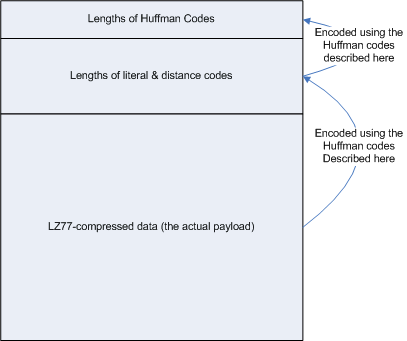
'A' : 길이 1
'B' : 길이 3
'C' : 길이 3
'D' : 길이 3
허프만 트리는 “각 심볼의 코드 길이”만 알면 똑같이 재구성할 수 있다고 한다
심볼(symbol) = 압축 알고리즘이 “하나의 단위로 취급해서 인코딩/디코딩하는 최소 의미 조각”
디코딩 순서
1. 허프만 코드 길이 정보 읽기
2. 동일한 허프만 트리 재구성
3. 비트 스트림을 한 비트씩 읽음
4. 리프 노드 도착 → 심볼 확정
5. 반복
그렇기때문에 Prefix Code 필수!!! 무조건 끊을수있어야함
참고)
정리가 아주 깔끔하게 되어있다.
알고리즘 - 5. 파일압축 & 암호화
1. Huffman Encoding 2. 암호화 기법
velog.io
'유니티' 카테고리의 다른 글
| unity MVP vs MVVM (0) | 2026.02.04 |
|---|---|
| 유니티 커서 ai 한글깨짐 해결 방법����(utf-8) (0) | 2026.02.04 |
| UNITY videoPlayer 오브젝트에 영상 실행 (0) | 2026.01.27 |
| Unity WebGLInput 입력 누적 문제 해결(InputField) (1) | 2026.01.22 |
| Slider Value 변경 안먹음 에러 해결(clamp, lerp) (0) | 2026.01.13 |